 自主训练
自主训练
第一步:创建训练任务

点击新建任务

选择你想要训练的模型目标类型
第二步:数据导入
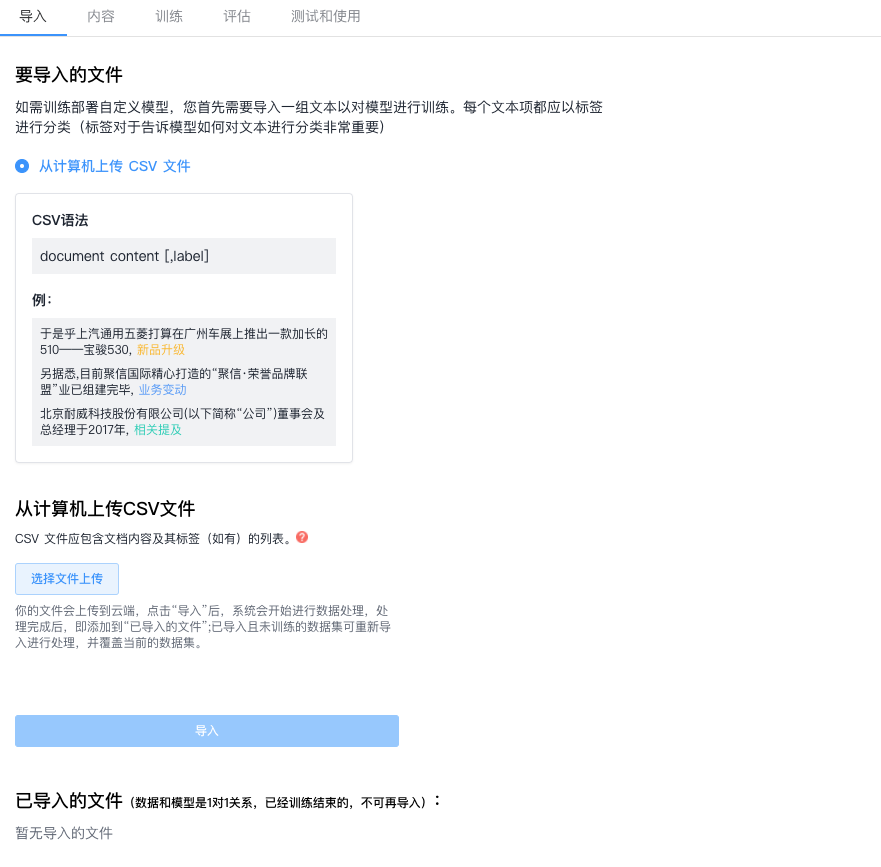
- 1. 在导入页面选择要向其导入文档的数据集类型
- 2. 上传文件,从本地选择要导入的文件
- 3. 点击导入
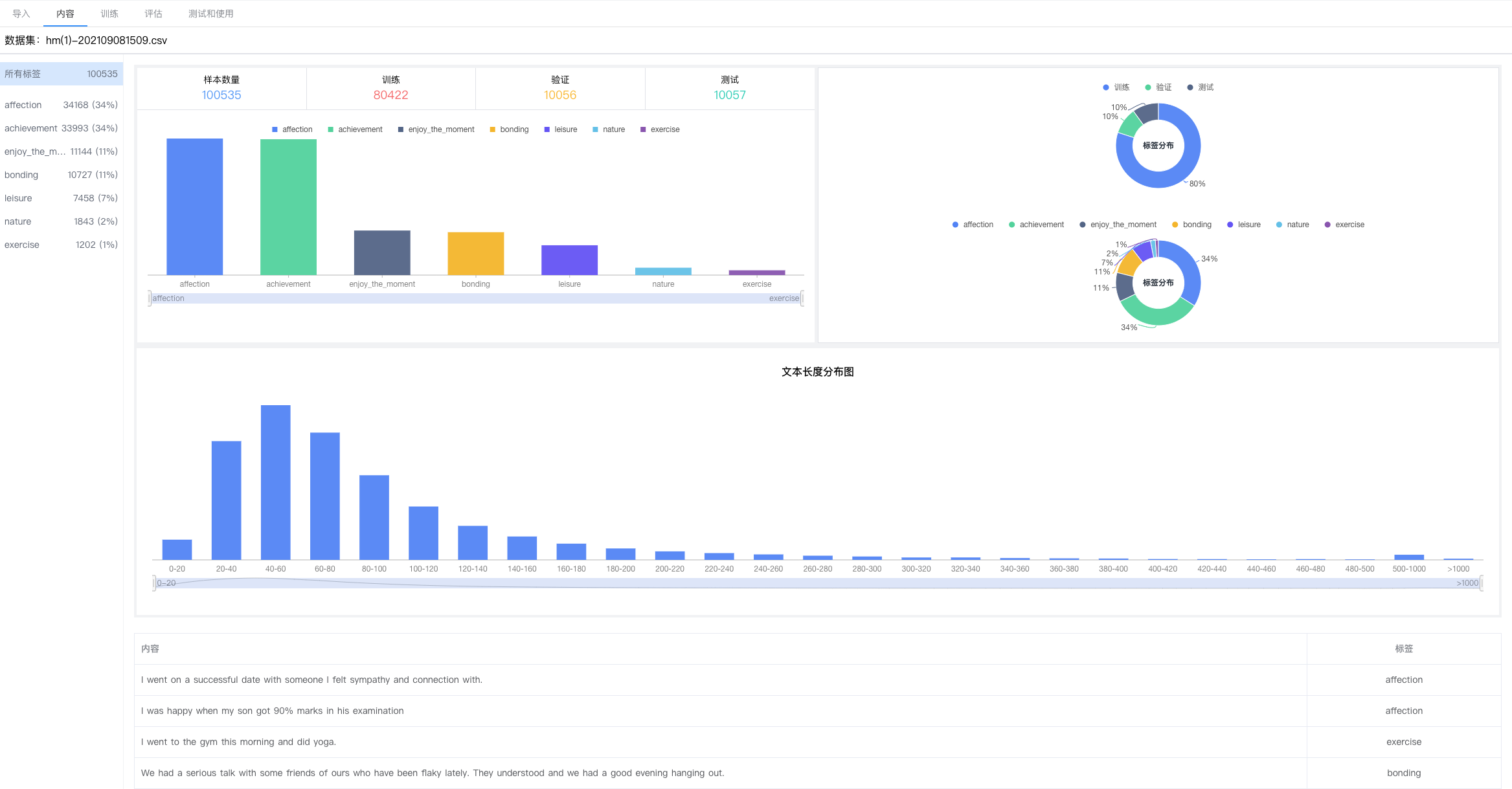
第三步:数据透视
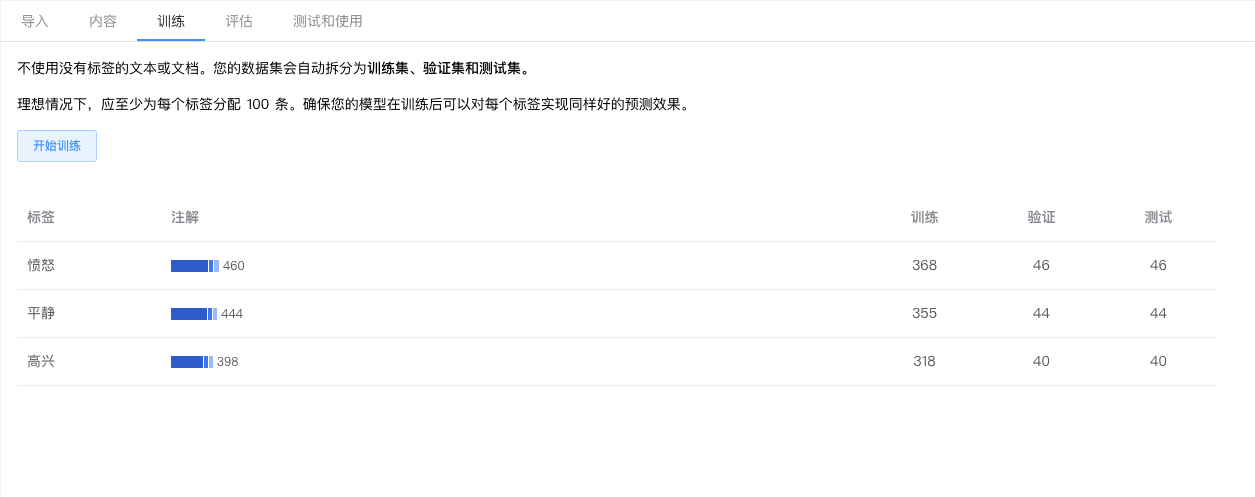
第四步:训练模型
训练模型可能需要几个小时才能完成。所需要的训练时间取决于多种因素,例如数据集的大小、训练项的性质以及模型的复杂程度。
第五步:评估模型
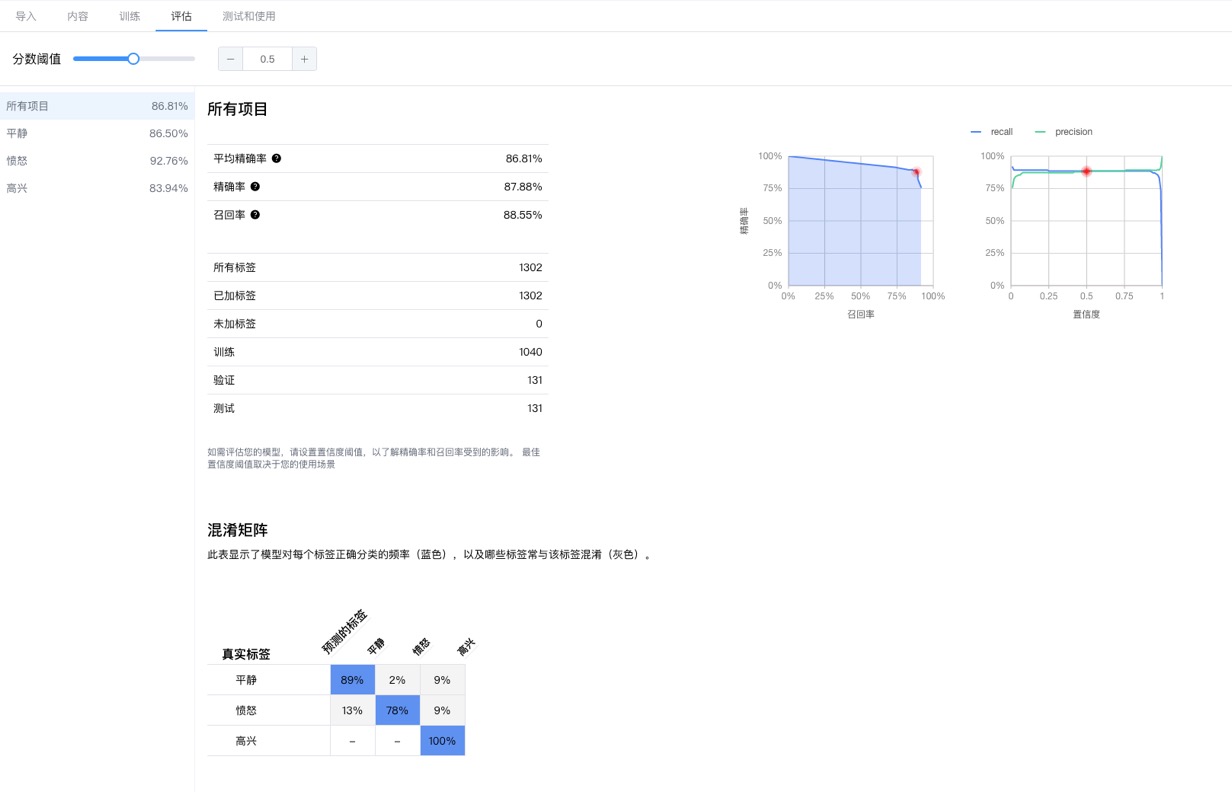
模型训练完成后,您将收到模型性能总结。请按一下评估或者查看完整评估。
- 1. 模型输出:模型会针对每个样本输出一系列数字,用于表示每个标签与该样本相关的程度。
- 2. 分数阈值:分数阈值是指要将某一个类别分配给某一个测试文本,模型必须具有的置信度水平。界面中的分数阈值滑块是一种直观的工具,用于测试不同阈值对数据集的影响。
- 3. 精确率和召回率用于衡量模型捕捉信息的情况以及丢失的信息量。通过精确率指标可以了解到,在被模型识别为特定标签的特定测试样本中,实际有多少样本是真正数据该标签。通过召回率指标可以了解到,在实际为某个特定标签的样本中,实际有多少样本被模型识别成了该标签。
- 4. 混淆矩阵:混淆矩阵表示评估期间每个标签的文本被预测为训练集内相应标签的次数百分比。在理想模型中,对角线上的所有值都将很高,而所有其他值都将很低。 这表明目标类别都得到了正确识别。如果有其他任何值较高。
- 5. 精确率/召回率曲线:通过分数阈值工具,您可以研究所选分数阈值会如何影响您的精确度和召回率。当您拖动分数阈值栏上的滑块时,您可以看到该阈值会将您置于精确率/召回率权衡曲线的什么位置,以及该阈值如何分别影响您的精确率和召回率(对于多类模型,这些图表上的精确率和召回率意味着用于计算精确率和召回率指标的唯一标签是我们返回的标签集中分数最高的标签)。这可以帮助您在假正例和假负例之间找到一个很好的平衡点。
- 6. 平均精确率:精确率与召回率曲线下的面积是衡量模型准确率的有用指标。它衡量模型在所有分数阈值上的表现。 此指标称为“平均精确率”。此分数越接近 1.0,您的模型在测试集上的表现越好;如果是随机猜测使用哪个标签的模型,平均精确率约为 0.5。
第六步:测试和使用
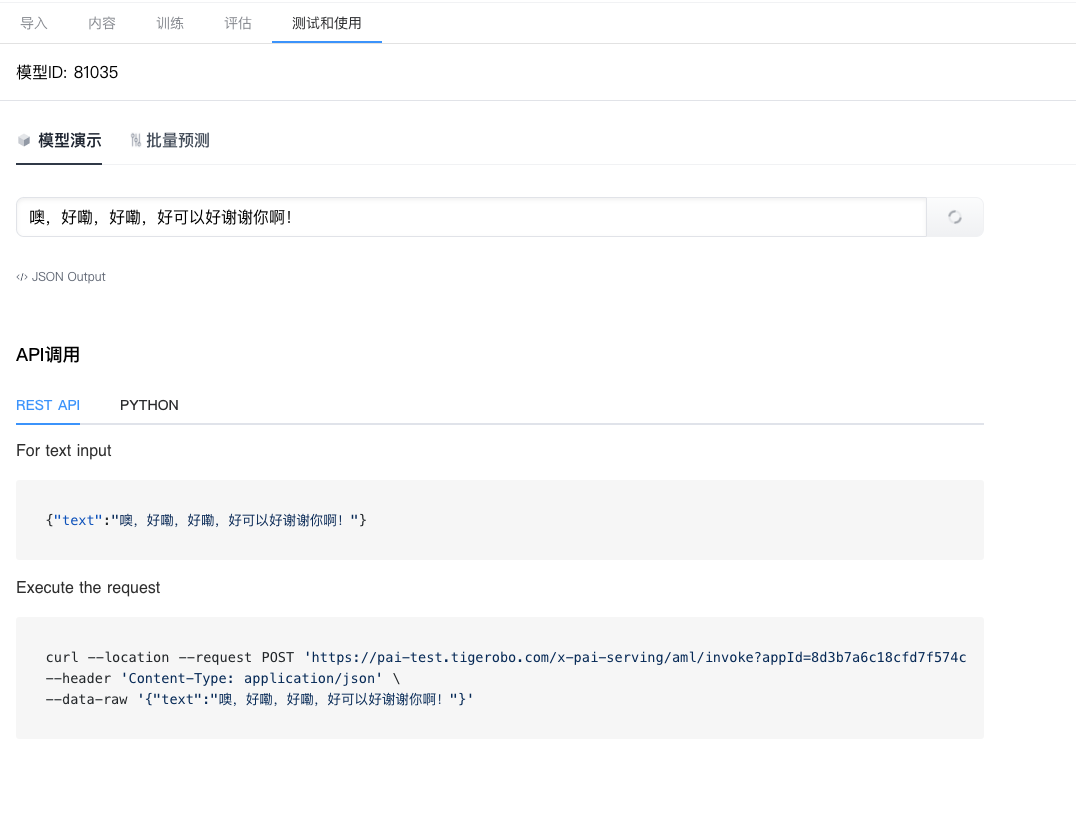
- 你可以:
- 1. 输入文本,输出结果。
- 2. 查看结果的json数据
- 3. REST API 调用
- 4. Python API 调用
- 5. 批量测试